我把 Claude Code 的「大脑」移植到了 Pi Agent 里
Claude Code 是现在最强的 coding agent 之一,它的 system prompt 是最值得学习的 agent 资源之一。我把它移植到了开源框架 Pi Agent 里。
Claude Code 的 system prompt 并没有官方开源,但是https://cchistory.mariozechner.at/ 可以看到所有的版本迭代记录。
Claude Code 是现在最强的 coding agent 之一,它的 system prompt 是最值得学习的 agent 资源之一。我把它移植到了开源框架 Pi Agent 里。
Claude Code 的 system prompt 并没有官方开源,但是https://cchistory.mariozechner.at/ 可以看到所有的版本迭代记录。
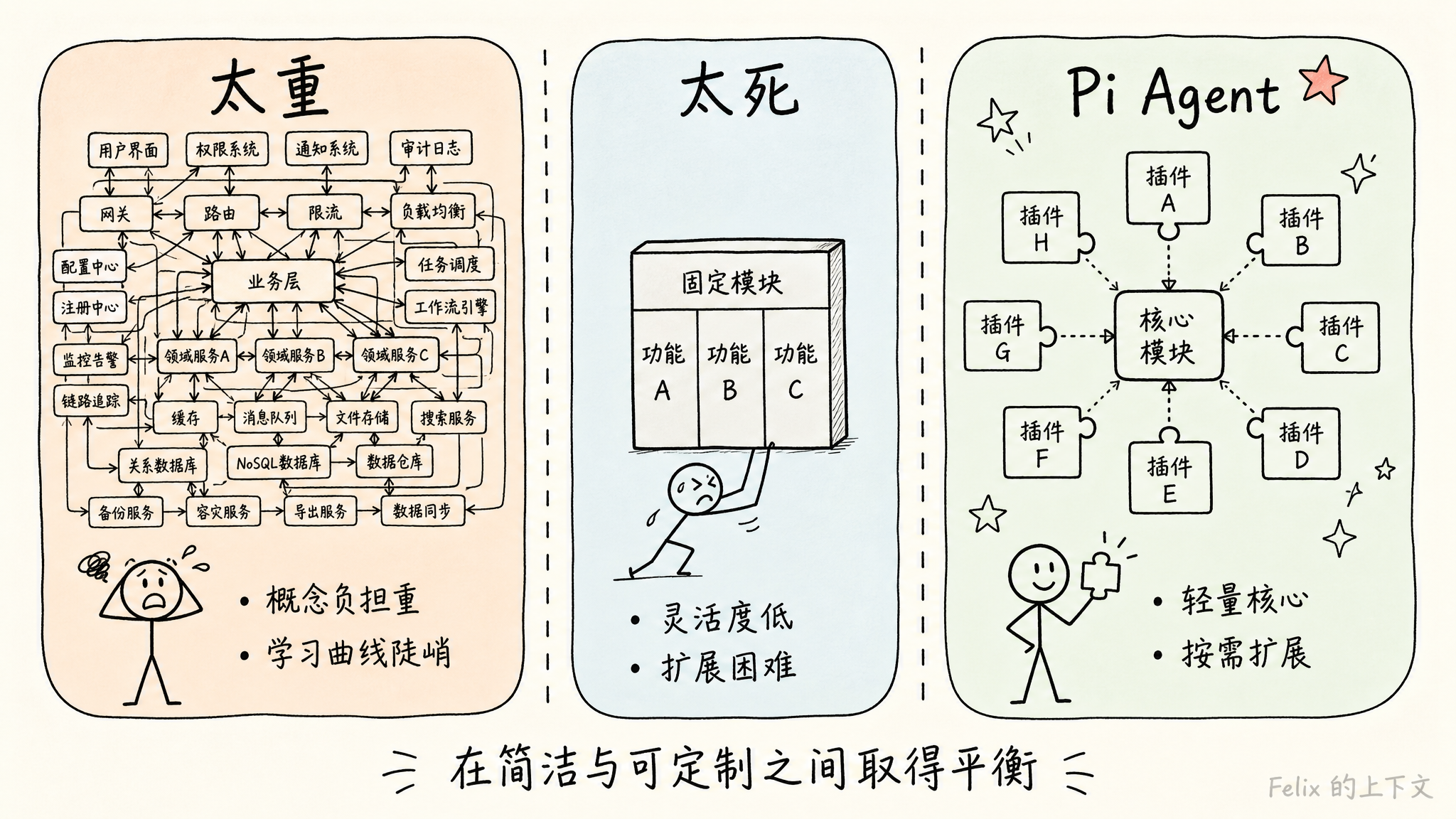
AI Agent 的概念火了两年,开源社区里相关的框架也长出了一大片。翻一圈下来会发现一个问题:大多数框架要么「太重」,要么「太死」。
太重的那一类——架构宏大、概念层叠,还没开始写第一行定制代码,光理解框架本身的命名和约定就耗尽了热情。太死的那一类——倒是不复杂,但稍微想加点自定义行为,就发现处处碰壁,框架在设计上根本没有给你留入口。
Claude Code 能在一个会话里持续工作很久——搜索代码、读文件、改代码、跑测试、看报错、再改——这个过程可能涉及几十轮工具调用。但每一次工具调用的结果都会塞进对话历史:一个 grep 搜索可能返回几千行,一个 cat 可能读出整个文件。不到十轮,200K 的上下文窗口就可能被塞满。
然而你几乎感受不到这个限制。它从来不会突然说”对不起,上下文满了,我们得重新开始”。
源码揭示了背后的机制:一套 6 层渐进式压缩架构,从工具执行的那一刻起就在控制上下文膨胀,直到最终的对话摘要。每一层成本递增、破坏性递增,系统总是优先用最轻量的方式解决问题。

有一些 AI Agent 产品,你问它一个问题,它思考一下、调用一两次工具,然后就给你个回答,结束了。哪怕任务还没做完,它也像”到点下班”一样停下来了。
但 Claude Code 不一样。你跟它说”帮我重构这个认证模块”,它会自己去搜索代码、阅读文件、分析依赖关系、动手改代码、跑测试、发现测试挂了、再改、再跑……直到任务真正完成。整个过程可能会经历几十轮工具调用,完全不需要你中间催它。
opencode 是一个对新手非常友好的 AI 编程工具:
自带免费的大模型可用
零配置上手,在项目目录里直接使用
开源,能直接看源码,对想学 Agent 的人来说,也是一份非常不错的学习资料
最近看到很多人都在推荐 opencode。我自己其实已经用习惯了 claude code 和 codex,本来不打算折腾新的工具。但架不住推荐的人实在太多,还是试了一下……结果现在我也想推荐它了。
大家估计看过很过大模型的评测。基本上都是设想几个编程场景,然后用几个不同的模型进行对比。
但在真实的工作场景中,我们面对的更多是一个已经存在、可能庞大复杂的代码库。要在这样的代码库中理解架构、找到关键信息、做出正确修改,这才是真正的挑战。
这次,我让kimi k2 thinking 面对了一个地狱级考验:在拥有 8 万行代码、500 多个文件的 MkSaaS 模板库中,开发一个”纳瓦尔语录”网站。
前几天看到一个帖子。

我其实也一直很好奇这个问题。
我大概两个月前开始做一个抖音账号。
因为是业余时间做的,基本上都是下班路上随便找个地方坐下来讲一些话题,或者就是在书房录制一些视频。算是佛系更新吧。
我前天没有啥话题,正好在南京南的站台上有很多人抽烟,我就随手拍了一张照片吐槽一下。没想到因为这个只有一张照片的短视频,我被喷惨了。